Ahora ya podemos conectarnos a una base de datos y gestionar los errores correctamente, de manera que ha llegado la hora de que su programa realice un trabajo real. La función API principal para ejecutar las sentencias SQL es:

Esta rutina adopta el indicador de la estructura de conexión y algún SQL válido en modo de cadena de texto (sin el punto y coma final, como en la herramienta mysql). Si tiene éxito recibirá un cero. Se puede usar una segunda rutina, mysql_real_query, si se solicitan datos binarios, pero en este capítulo vamos a usar solo mysql_query.
Sentencias SQL que no devuelven datos
Simplificando, observaremos algunas sentencias SQL que no envían ningún dato:
UPDATE, DELETE e INSERT.
Veamos otra función importante que es la encargada de comprobar el número de filas a las que afecta la consulta:

Debemos tener en cuenta el tipo de datos poco común que envía esta función. Se trata de un tipo sin firma que se usa por cuestiones de portabilidad. Cuando esté usando printf, se recomienda su emisión sin firmar junto con un formato de %lu. Esta función envía el número de líneas a las que afectan las consultas UPDATE, INSERT y DELETE emitidas previamente. Dicho valor de retorno podría cogernos desprevenidos si previamente hemos trabajado con otras bases de datos SQL. MySQL envía el numero de filas modificado por una actualización, mientras que la mayoría de bases de datos tendrían en cuenta un registro actualizado, únicamente porque se corresponde con cualquier cláusula WHERE.
Generalmente, con la funciones mysql_, un retorno de 0 indica que no ha afectado a ninguna fila y un número positivo es el resultado real, normalmente el número de filas afectadas por la sentencia.
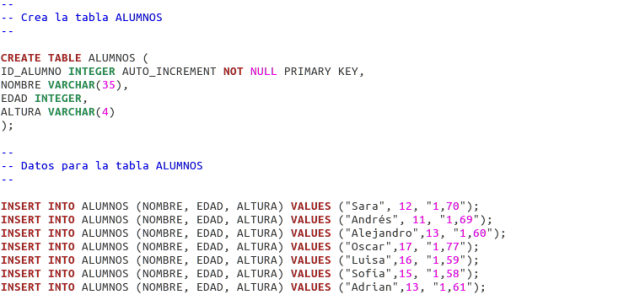
Lo primero que tenemos que hacer es crear una tabla de ALUMNOS en la base de datos loquesea, si aún no lo ha echo. Elimine (usando el comando drop) cualquier tabla existente para asegurar que dispone de una definición de tabla totalmente vacía, y para volver a enviar cualquier ID usada en la columna AUTO_INCREMENT:
 Luego añadimos el listado del archivo
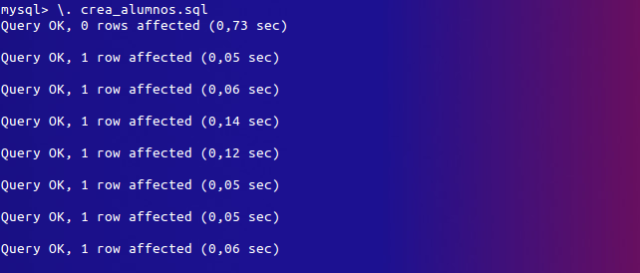
Luego añadimos el listado del archivo crea_alumnos.sql que hemos creado previamente:
Dentro de la consola de comandos del MySQL escribimos:
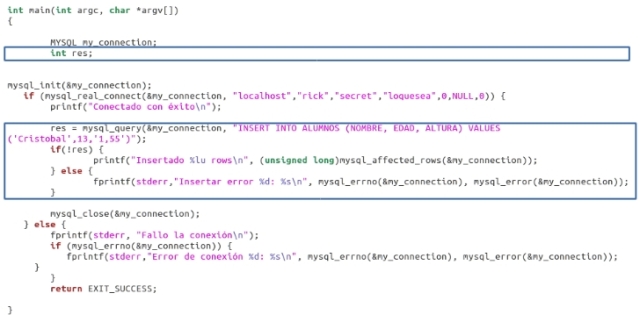
Añadimos ahora código a connect2.c con el fin de insertar una nueva fila en la tabla. Llamaremos este nuevo programa insert1.c.
Si lo compilamos y ejecutamos tendremos la salida:

y desde la consola MySQL:
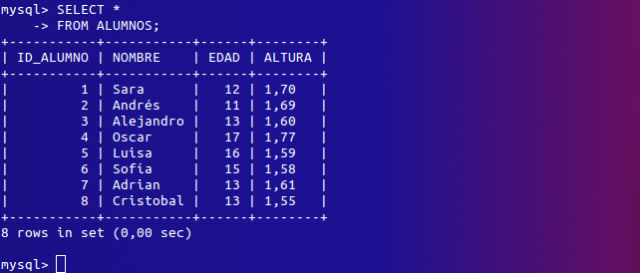
Vemos que la línea se a insertado satisfactoriamente.
Ahora modificaremos el código para incluir un UPDATE, en vez de INSERT, y verá cómo se informa de las líneas afectadas:
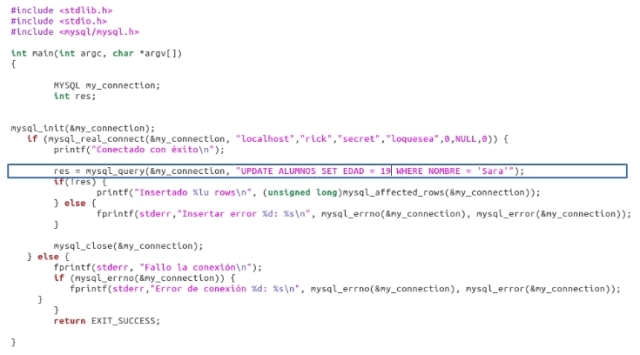
Llame a este programa update1.c. Éste intenta establecer la edad de todas los alumnas que se llamen Sara en 19 años:
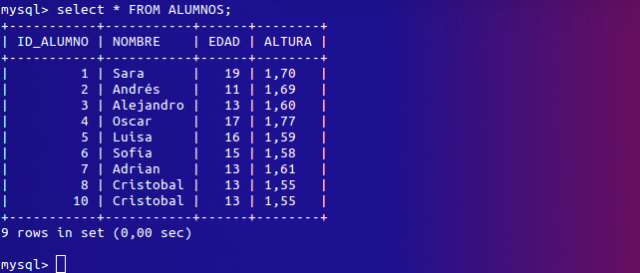
Descubrir lo que hemos insertado
Tenemos un pequeño aspecto crucial a tener en cuenta en lo relativo a la inserción de datos. Si miramos al pasado de este curso/tutorial, mencionamos un tipo de columna llamada AUTO_INCREMENT, que usaba MySQL para asignar una ID automática. Esta prestación es realmente muy útil, sobre todo si existen varios usuarios.
Veamos nuevamente la definición de la tabla:
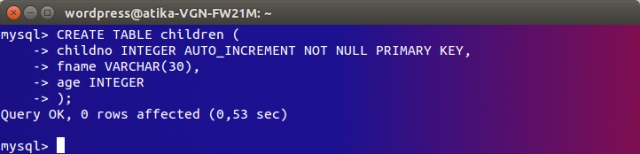
Vemos. que la columna childno es un campo AUTO_INCREMENT.
Todo correcto, pero ¿como sabremos que número se ha asignado cada vez que ponemos un dato? Podemos ejecutar la sentencia SELECT (tal como vemos en la ilustración de abajo) para recuperar los datos, buscando el nombre del niño pero es poco eficiente, y no se garantiza que sea el único (posiblemente existan dos niños con el mismo nombre). O podemos encontrarnos que varios usuarios inserten al mismo tiempo, y se podrían insertar, por tanto, otras filas entre su actualización y su sentencia SELECT.

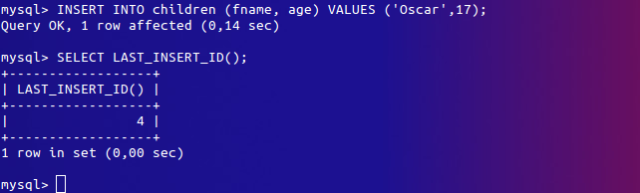
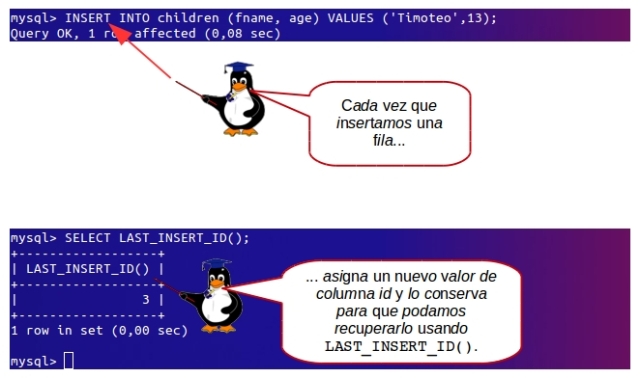
Como podríamos descubrir el valor de una columna AUTO_INCREMENT suele ser un problema común, MySQL proporciona una solución especial a modo de función LAST_INSERT_ID(). Siempre que MySQL inserta un valor de datos en una columna AUTO_INCREMENT, se conserva, basándose en el usuario, el último valor asignado. Los programas de los usuarios pueden recuperar este valor seleccionado (mediante SELECT) la función un poco especial LAST_INSERT_ID(), que actúa de algún modo como una pseudo columna.
Recuperar la ID generada por AUTO_INCREMENT
Vamos a ver como funciona insertando algunos valores en nuestra tabla,
![]() y usando después la función
y usando después la función LAST_INSERT_ID().

Insertemos otro registro:
Cómo funciona
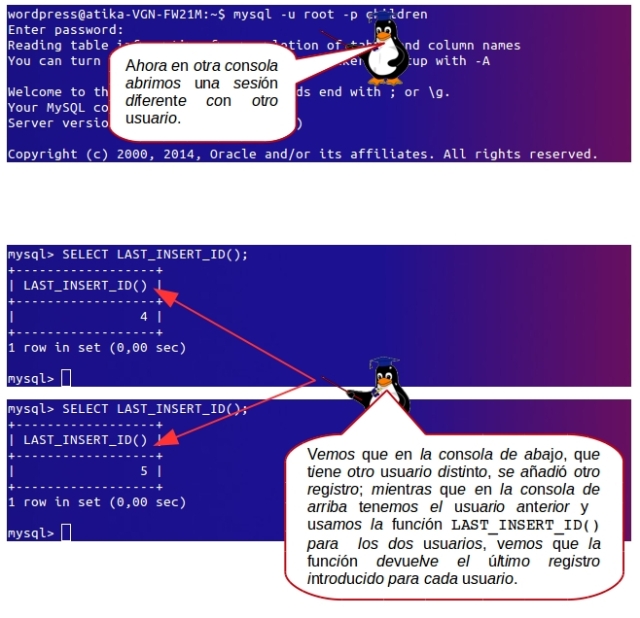
Si desea experimentar para comprobar que el número enviado es, de hecho, único para su sesión, abra una sesión diferente e inserte otra fila. En la sesión original, vuelva a ejecutar la sentencia SELECT LAST_INSERT_ID();. Verá que el número no ha variado porque el número enviado es el último introducido por la sesión actual. Sin embargo, si ejecuta SELECT * FROM, verá que la otra sesión sí que ha insertado datos.
Uso de ID automáticas a partir de un programa C
En este ejemplo, vamos a modificar el programa insert1.c para ver como trabaja en C. Llamemos a este programa insert2.c:
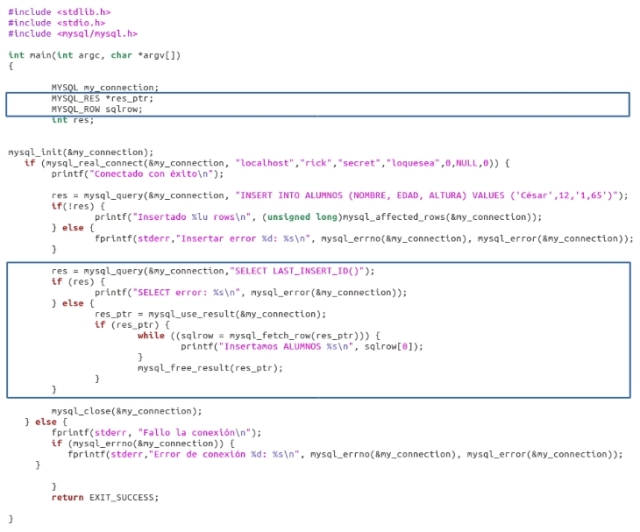
La salida sería:

Sentencias que retornan datos
El uso más frecuente de SQL es, por supuesto, recuperar más que insertar o actualizar los datos. Los datos se recuperan con la sentencia SELECT.

La recuperación de datos en su aplicación C se hace en cuatro pasos:
- Emitir la consulta.
- Igual que hicimos con
INSERTyDELETE, usarámysql_querypara enviar SQL.
- Igual que hicimos con
- Recuperar los datos.
- A continuación recuperará los datos usando
mysql_store_resultomysql_use_result(dependiendo de cómo quiera recuperar dichos datos).
- A continuación recuperará los datos usando
- Procesar los datos.
- Posteriormente usará una secuencia de llamadas
mysql_fetch_rowpara procesar los datos. Por último, usarámysql_free_resultpara vaciar la memoria que usó para realizar la petición. La diferencia entremysql_use_resultymysql_store_resultreside básicamente en si deseamos obtener los datos fila por fila o todo junto.
- Posteriormente usará una secuencia de llamadas
- Organizarlos si se necesita.
- El último es más apropiado si creemos que los resultados van a ser un conjunto de resultados más pequeños.
Funciones para recuperar todos los datos a la vez
Podemos recuperar todos los datos a partir de SELECT (o cualquier otra sentencia que recupere datos), a través de una única llamada, usando mysql_store_result:
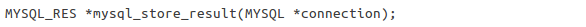 Evidentemente, querrá usar esta función tras una llamada con éxito a
Evidentemente, querrá usar esta función tras una llamada con éxito a mysql_querry. La función almacenará todos los datos retornados al cliente inmediatamente. Enviará un indicador de posición de una nueva estructura denominada estructura de conjunto de resultados, o NULL si la sentencia falla. Si tiene éxito, a continuación llamará a mysql_num_rows para obtener el número de registros retornados, que esperamos sea un número positivo (puede ser cero si no se ha enviado ninguna fila).

Adopta la estructura de resultado enviada desde mysql_store_result y envía el número de filas en dicho conjunto de resultados. Siempre que mysql_store_result tenga éxito, mysql_num_rows tendrá éxito. Esta combinación de funciones es un modo sencillo para recuperar los datos necesarios. En este momento, todos los datos se encuentran en el entorno local del cliente y ya no tendrá que preocuparse por los errores de red o de base de datos. Mediante la obtención del número de filas retornadas, facilitará la codificación que queda por hacer.
Si estamos trabajando con un conjunto de datos bastante grande, sería mejor recuperar algunos fragmentos de información más pequeños y manejables. Esto le devolverá el control a la aplicación más rápidamente y es un método para usar los recursos de la red desinteresadamente.
Ahora ya disponemos de datos, los podemos procesar usando mysql_fetch_row y moverse por el conjunto de datos usando mysql_data_seek, mysql_row_seek y mysql_row_tell. Veamos estas funciones:
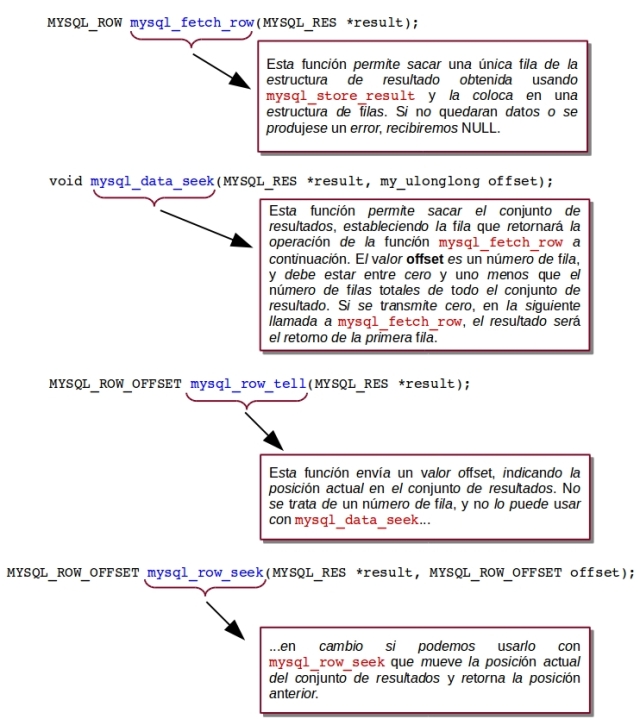
 Esta pareja de funciones es más útil para moverse entre puntos conocidos en el conjunto de resultados. Tenga cuidado de no confundir el valor offset usado por
Esta pareja de funciones es más útil para moverse entre puntos conocidos en el conjunto de resultados. Tenga cuidado de no confundir el valor offset usado por row_tell y row_seek con el row_number usado por data_seek. Los resultados serían imprevisibles.

Recuperación de datos
Bueno, ya estamos listos para escribir nuestra primera aplicación de recuperación de datos. Lo que haremos es recuperar todos los registros en los que la edad sea superior a cinco. Aún no sabemos cómo procesar los datos, de manera que lo único que vamos a hacer por el momento es recuperarlos. Llamaremos a esta aplicación select1.c.
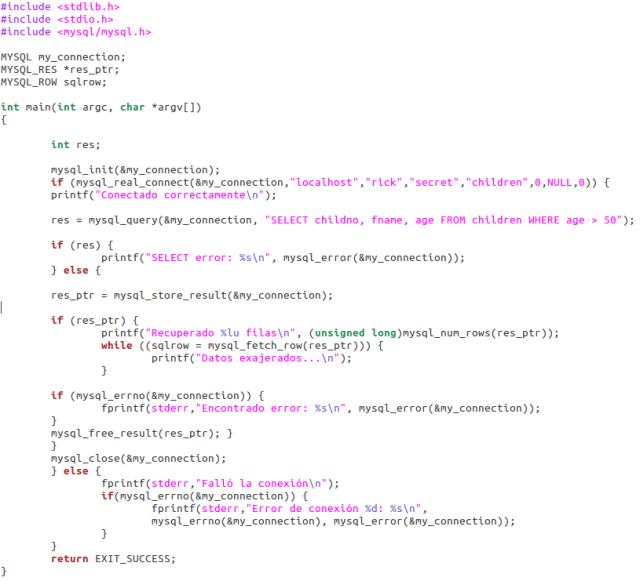
Recuperar datos fila a fila
Para recuperar datos fila a fila que es lo que queremos hacer realmente, debe usar mysql_use_result en vez de mysql_store_result:

Igual que con la función mysql_store_result, mysql_use_result envía NULL si falla, y si tiene éxito envía un indicador de un objeto del conjunto de resultados. Sin embargo, se diferencia porque no ha recuperado ningún dato en el conjunto de resultados que ha iniciado.
 Debe usar
Debe usar mysql_fetch_row repetidamente hasta que se hayan recuperado todos los datos con el fin de obtener los datos. Si no obtiene todos los datos de mysql_use_result, las operaciones posteriores que realice su programa para recuperar datos podrán devolver una información errónea.
¿Que pasaría si en vez de llamar a mysql_use_result llamáramos a mysql_store_result? Si usamos el primero contamos con muchos beneficios en lo referente a la gestión de los recursos, pero, no podremos usarlo con mysql_data_seek, mysql_row_seek, o mysql_row_tell, y la utilidad mysql_num_rows está limitada por el hecho de que realmente no comienza a funcionar hasta que no ha recuperado todos los datos.
Sin embargo ninguno de estos aspectos disminuye de ningún modo los beneficios nombrados anteriormente: una carga de red con un mejor equilibrio y menos gastos de almacenaje para posibilitar grandes conjuntos de datos.
Modifiquemos el listado select1.c y hacemos los siguientes cambios llamando al programa select2.c:

Observaremos que sigue sin poder obtener un recuento de filas hasta que se consiga el último resultado.

Sin embargo, si comprueba los errores frecuentemente y pronto, hará que podamos aplicarlo mucho más fácilmente el cambio a mysql_use_result. Esta codificación nos puede ahorrar dolores de cabeza en posteriores modificaciones de la aplicación.
Procesando los datos retornados
Bueno hemos aprendido a recuperar filas, ahora ya podemos procesar los datos realmente retornados. MySQL, al igual que otras muchas base de datos, proporciona dos clases de datos:
- La información recuperada de la tabla, llamados datos de columna.
- Los datos sobre los datos, comúnmente conocidos como meta datos, tal como nombres de las columnas y de sus tipos.
Veamos primero los datos propios dentro de un formulario utilizable. La función mysql_field_count proporciona información básica sobre el resultado de la consulta. Adopta su objeto de conexión y retorna el número de campos (columnas) en el conjunto de los resultados:
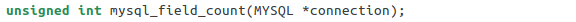
Podemos usar de un modo más genérico mysql_field_count para otras cosas, como averiguar porqué falló una llamada a mysql_store_result. Por ejemplo, si mysql_store_result envía NULL, pero mysql_field_count envía un número positivo, puede insinuar que se ha producido un error de recuperación. Sin embargo, si mysql_field_count retorna 0 significará que no existían columnas para recuperar, lo cual explicaría el fallo a la hora de almacenar el resultado. Es normal querer saber el número de columnas que, supuestamente, devolverá una consulta en particular. Sin embargo, esta función es más útil con componentes de consultas genéricos o en una situación en las que las consultas se construyan sobre la marcha.
 En el código escrito para las versiones más antiguas de MySQL
En el código escrito para las versiones más antiguas de MySQL mysql_num_fields, que puede adoptar tanto una estructura de conexión como un indicador de estructura de resultados y enviar el número de columnas.
Dejando a un lado los aspectos referentes al formato, ya sabe cómo mostrar los datos correctamente. Añadiremos una sencilla función display_row al programa select2.c.
Tenga en cuenta que ha hecho que la conexión, el resultado y la información de la fila enviada por mysql_fetch_row, sean globales para simplificar el ejemplo. Para la producción de código no se recomienda su uso.

Debe estar conectado para enviar un comentario.