Todas las versiones de Linux, y la mayoría de versiones UNIX, incluyen un conjunto de rutinas de almacenaje de datos muy básicas y eficientes denominado base de datos dbm. La base de datos dbm es perfecta para almacenar los datos indexados que son relativamente estáticos. Algunos puristas de las bases de datos pueden argumentar que dbm no es una base de datos de ningún modo, y que se trata únicamente de un sistema de almacenamiento de archivos indexados. Sin embargo, las especificaciones X/Open, trata a dbm como una base de datos, por eso vamos a seguir llamándola base de datos.
Introducción a dbm
 A pesar del aumento de las bases de datos relacionales gratuitas, como MySQL, y PostgresSQL, la base de datos
A pesar del aumento de las bases de datos relacionales gratuitas, como MySQL, y PostgresSQL, la base de datos dbm sigue jugando un importante papel en Linux. Las distribuciones que usan RPM, como Red Hat y SUSE, usan dbm como el método de almacenaje subyacente para la información de los paquetes instalados. La implementación de código abierto de LDAP, Open LDAP, también puede usar dbm como mecanismos de almacenaje. La ventaja de dbm ante una base de datos completa como MySQL es que es mucho más ligera, y mucho más fácil de crear en un binario distribuido, ya que no hacen falta instalaciones de servidor de base de datos independientes.
La base de datos dbm le permite almacenar estructuras de datos de diferentes tamaños, usando un índice, y recuperando después la estructura ya sea mediante un índice o escaneando consecutivamente la base de datos. La base de datos dbm es mejor para los datos a los que se acceden con frecuencia pero que no se actualiza casi nunca, ya que tiende a ser bastante lenta creando entradas pero es muy rápida recuperándolas.
Hasta la fecha surgieron variaciones de la base de datos dbm con API y prestaciones un poco diferentes. Actualmente se utiliza el nuevo conjunto dbm llamado ndbm, y la implementación GNU, gdbm. La implementación GNU puede emular también las interfaces dbm y ndbm antiguas, pero tienen una interfaz distinta a las de las otras implementaciones. Las diferentes versiones Linux contienen diferentes versiones de la biblioteca dbm, a pesar de que la opción más común es la biblioteca gdbm, instalada de manera que pueda emular a las otras dos interfaces.
Aquí nos centraremos en la interfaz ndbm porque es la que ha estandarizado X/Open y porque es más sencilla que la implementación gdbm.
Localización de problemas y reinstalación de dbm
Se supone que dispone Ud., de la implementación GNU de gdbm instalada, junto con las bibliotecas ndbm compatibles. Con las distribuciones Linux suele ser así, sin embargo, es posible que tenga que instalar explícitamente el paquete de desarrollo de biblioteca con el fin de compilar los archivos usando las rutinas ndbm.
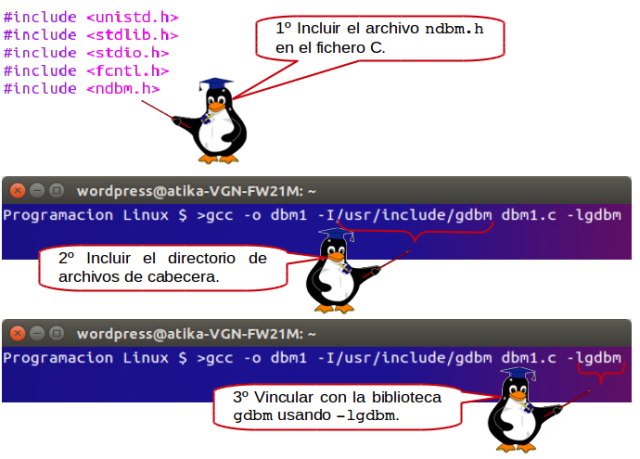
Desafortunadamente, la biblioteca incluida y la de enlace necesarias varían dependiendo de la distribución, de manera que aunque esté instalada, es posible que tenga que experimentar un poco para saber como compilar los archivos fuente usando ndbm. El caso más común es que gdbm esté instalada y que acepte, por defecto, el modo de compatibilidad ndbm. Las distribuciones RedHat, por ejemplo, suelen hacerlo así. En este caso tendrá que:
Si esto no funciona, otra opción común, usada por las distribuciones Ubuntu y SUSE, es que gdbm esté instalada, pero tendremos que solicitar expresamente la compatibilidad ndbm si fuese necesario, y deberíamos vincular con la biblioteca de compatibilidad antes que con la biblioteca principal. En este supuesto tendrá que:
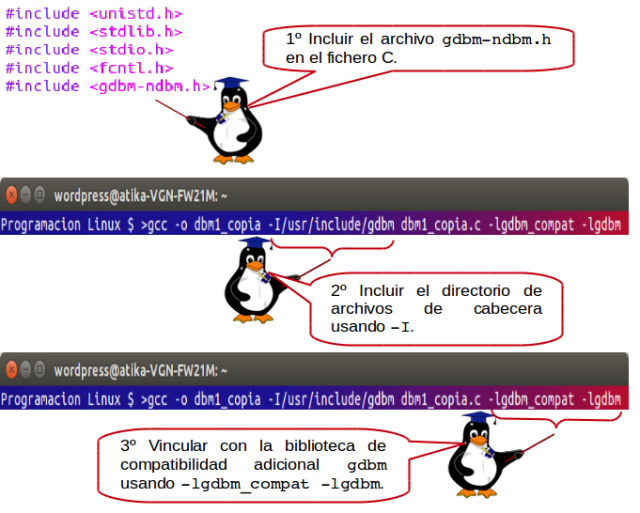
Los archivos C descargables Makefile y dbm están configurados, por defecto, según la primera opción, pero contienen comentarios sobre cómo han de ser editados para seleccionar fácilmente la segunda opción. Durante el resto del capítulo daremos por hecho que su sistema contiene la compatibilidad ndbm como el comportamiento preestablecido.
Las rutinas dbm
Al igual que curses, la prestación dbm está compuesta por un archivo de cabecera y una biblioteca y debe vincularse cuando se compila el programa. La biblioteca se denomina dbm, pero como, normalmente, usamos la implementación GNU de Linux, tenemos que vincularla con esta implementación usando -lgdbm en la línea de compilación. El archivo de cabecera es ndbm.h.
Antes de intentar explicar estas funciones, es importante comprender lo que está intentando conseguir la base de datos dbm. Cuando lo comprendamos, entenderemos mejor cómo funciona la mecánica de las funciones dbm.
El elemento básico de la base de datos dbm es un bloque de datos que hay que guardar, junto con un bloque acompañante de datos que actúa como la clave para recuperar los datos. Cada base de datos dbm debe tener una clave única para cada uno de los bloques de datos que ha de ser almacenado. El valor clave actúa como un índice de los datos guardados. No existe restricción alguna sobre las claves o sobre los datos, ni se han definido errores por usar datos o claves demasiado extensas. Las especificaciones permite una implementación para limitar el tamaño de la pareja clave/datos en 1023 bytes, pero normalmente no hay límite, porque las implementaciones han sido más flexibles de lo que debían ser.
Para manipular estos bloques de datos, el archivo incluido nbdm.h define un nuevo tipo denominado datum. El contenido exacto de este tipo depende de cada implementación, pero debe tener como mínimo los siguientes miembros:

datum es el tipo definido por typedef. En el archivo ndbm.h aparece también una definición de tipo para dbm, que es una estructura usada para acceder a la base de datos, al igual que se usa FILE para acceder a los archivos. Los internos de dbm typedef dependen de cada implementación y no deben usarse nunca.
Para referirse a un bloque de datos mientras esté usando la biblioteca dbm, debe declarar un datum, configurar dptr para que indique la parte inicial de los datos, y configurar dsize para que contenga su tamaño. El tipo datum hace referencia siempre tanto a los datos que hay que almacenar como al índice usado para acceder a dichos datos.
El tipo dbm se comprende mejor como análogo del tipo FILE. Cuando abre una base de datos dbm, se suelen crear dos archivos físicos: uno con extensión .pag y otro con extensión .dir. Se reenviará un único indicador dbm, que se usa para acceder a estos archivos directamente, ya que están pensados para acceder a ellos únicamente de las rutinas dbm.

Si está familiarizado con las bases de datos SQL, se habrá dado cuenta que no existe una columna de tabla o de columna asociada a una base de datos dbm. Estas estructuras no son necesarias porque dbm no impone un tamaño fijo a los elementos de los datos que han de ser almacenados, ni se les exige a los datos que contengan una estructura interna. La biblioteca dbm funciona con bloques de datos binarios desestructurados.
Funciones de acceso dbm
Tras haber presentado las bases de trabajo de una biblioteca dbm, ya podemos observar las funciones con todo detalle. Los prototipos para las principales funciones dbm son:

Veamos las funciones:
dbm_open
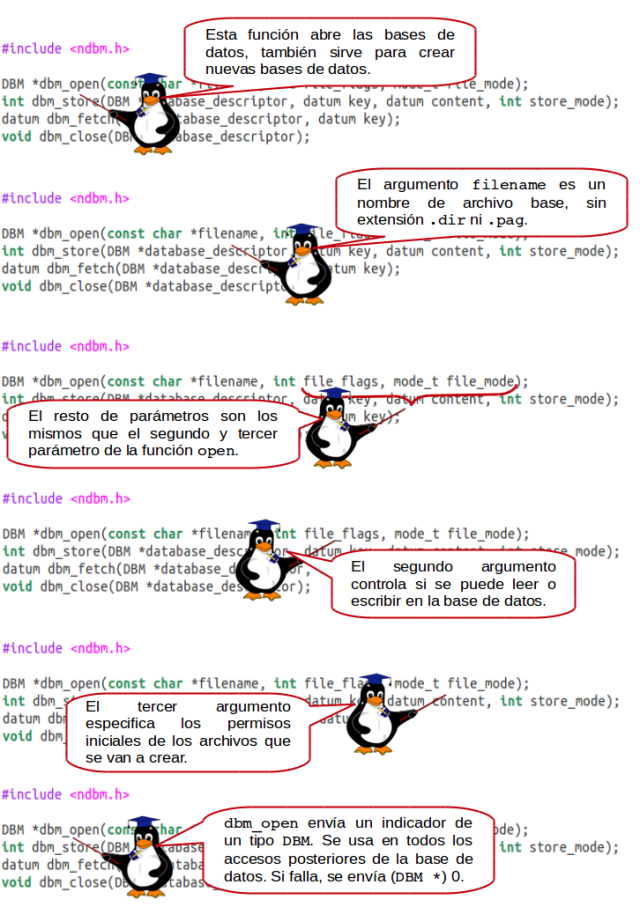
Si está creando una nueva base de datos, los indicadores deben ser O_READ con O_CREAT binarios para permitir la creación de archivos.
dbm_store
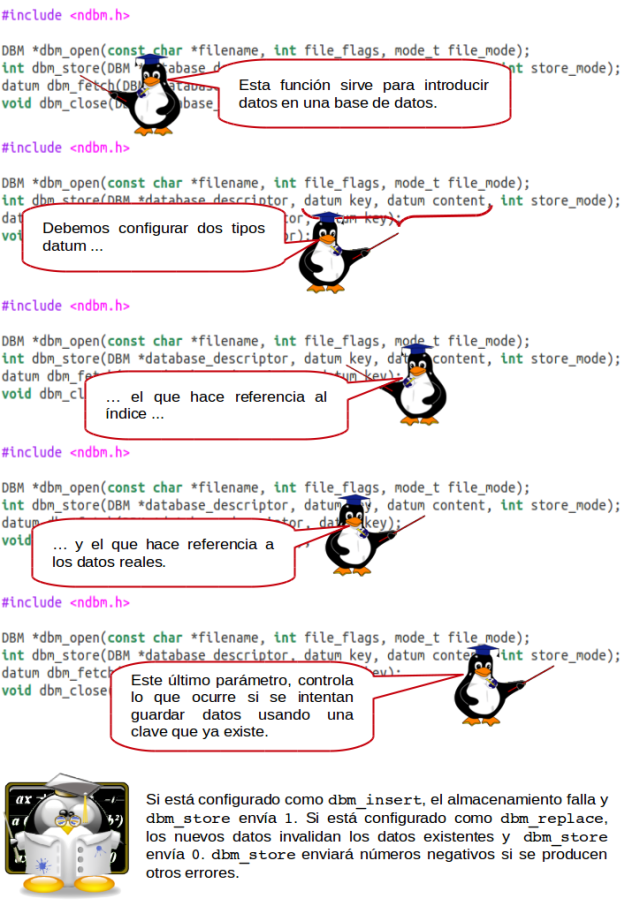
dbm_fetch


dbm_close

Una base de datos dbm sencilla
- En primer lugar, están los archivos
#includes,#defines, la funciónmain, y la declaración de la estructuratest_data: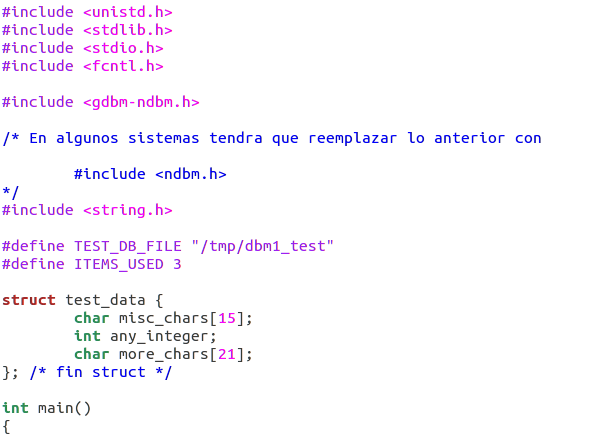
- Dentro de
main, configuramos las estructurasitems_to_storeeitems_received, la cadenakeyy los tiposdatums: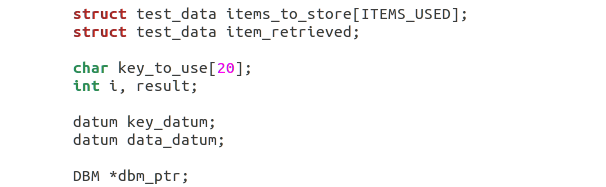
- Una vez que se ha declarado el indicador de una estructura tipo
dbm, abra su base de datos de prueba con acceso de lectura y escritura, creándola si fuese necesario:
- Añada ahora algún dato a la estructura
items_to_store: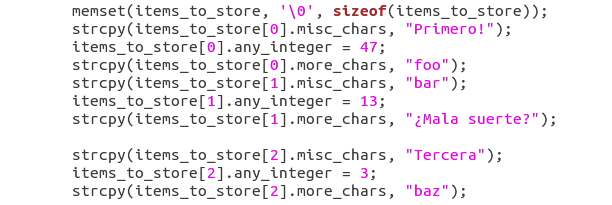
- Para cada entrada, ha de crear una clave para las futuras referencias. Se trata de la primera letra de una cadena y del entero. La clave será identificada después con
ky_Datum, mientras quedata_datumse refiere a la entradaitems_to_store. después debe guardar los datos en una base de datos: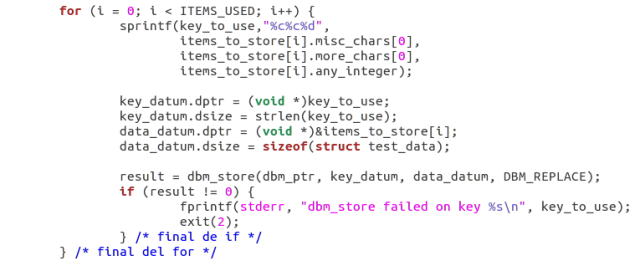
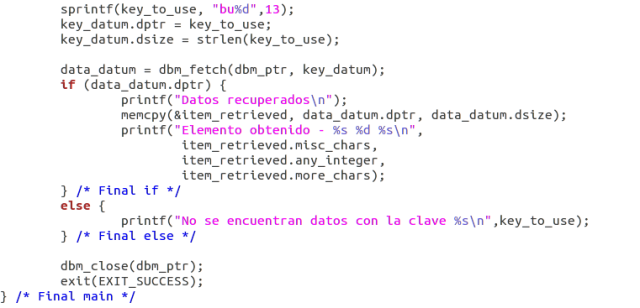
- A continuación y para terminar, observe si puede recuperar los nuevos datos, y después, finalmente, debe cerrar la base de datos:
Funciones dbm adicionales
Ahora que ya conoce las principales funciones dbm, podemos estudiar el resto de funciones que podemos usar con dbm:
 dbm_delete
dbm_delete

dbm_error

dbm_clearerr

dbm_firstkey y dbm_nextkey
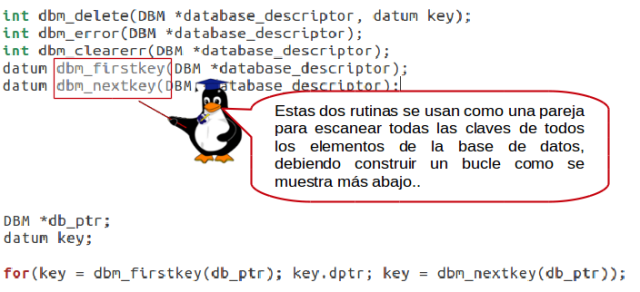
Recuperación y eliminación
Vamos a modificar dbm1.c y añadiremos algunas de las funciones que acabamos de ver para crear un nuevo archivo, llamado, dbm2.c:
- Primero copiaremos el archivo anterior dbm1.c y editamos la línea #define TEST_DB_FILE:
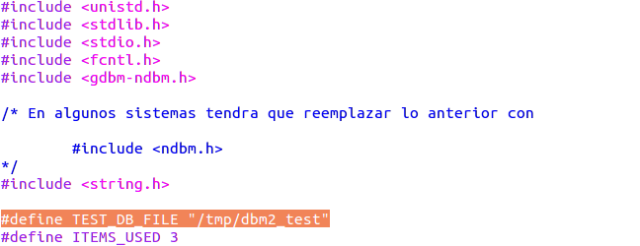
- Lo único que tiene que cambiar ahora se encuentra en la sección de recuperación:

La salida sería:
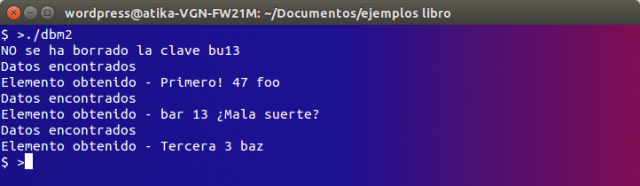
La primera parte del programa es idéntica al ejemplo anterior, lo único que hace es almacenar datos en la base de datos. después crea una clave que se corresponda con el segundo elemento y lo elimina de la base de datos.
El programa usa dbm_firstkey y dbm_nextkey para acceder a todas las claves de la base de datos una a una, recuperando los datos. Tenga en cuenta que los datos no se recuperan en orden, el orden clave no conlleva ningún tipo de orden de recuperación, es, sencillamente, un modo de escanear todas las entradas.


Debe estar conectado para enviar un comentario.