![]() Aunque podemos enviar y recibir datos manualmente mediante HTTP utilizando la librería socket, existe una forma mucho más simple para realizar esta habitual tarea en Python, utilizando la librería urllib.
Aunque podemos enviar y recibir datos manualmente mediante HTTP utilizando la librería socket, existe una forma mucho más simple para realizar esta habitual tarea en Python, utilizando la librería urllib.
![]() Utilizando urllib, es posible tratar una página web de forma parecida a un archivo. Se puede indicar simplemente qué página web se desea recuperar y urllib se encargará de manejar todos los detalles referentes al protocolo HTTP y a la cabecera.
Utilizando urllib, es posible tratar una página web de forma parecida a un archivo. Se puede indicar simplemente qué página web se desea recuperar y urllib se encargará de manejar todos los detalles referentes al protocolo HTTP y a la cabecera.
![]() El código equivalente para leer el archivo romeo.txt desde la web usando urllib es el siguiente:
El código equivalente para leer el archivo romeo.txt desde la web usando urllib es el siguiente:
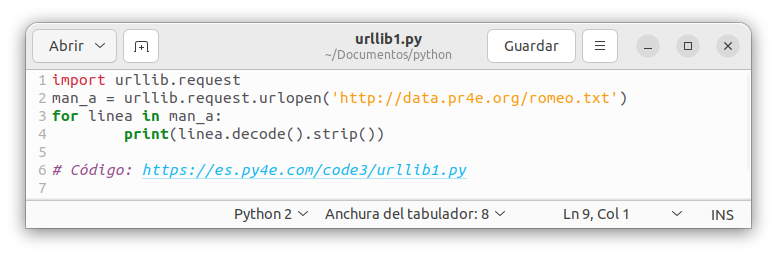
![]() Una vez que la página web ha sido abierta con urllib.request.urlopen, se puede tratar como un archivo y leer a través de ella utilizando un bucle for.
Una vez que la página web ha sido abierta con urllib.request.urlopen, se puede tratar como un archivo y leer a través de ella utilizando un bucle for.
![]() Cuando el programa se ejecuta, en su salida sólo vemos el contenido del archivo. Las cabeceras siguen enviándose, pero el código de urllib se encarga de manejarlas y solamente nos devuelve los datos.
Cuando el programa se ejecuta, en su salida sólo vemos el contenido del archivo. Las cabeceras siguen enviándose, pero el código de urllib se encarga de manejarlas y solamente nos devuelve los datos.

![]() Como ejemplo, podemos escribir un programa para obtener los datos de romeo.txt y calcular la frecuencia de cada palabra en el archivo de la forma siguiente:
Como ejemplo, podemos escribir un programa para obtener los datos de romeo.txt y calcular la frecuencia de cada palabra en el archivo de la forma siguiente:

![]() De nuevo vemos que, una vez abierta la página web, se puede leer como si fuera un archivo local.
De nuevo vemos que, una vez abierta la página web, se puede leer como si fuera un archivo local.



Debe estar conectado para enviar un comentario.