![]() A veces se desea obtener un archivo que no es de texto (o binario) tal como una imagen o un archivo de video. Los datos en esos archivos generalmente no son útiles para ser impresos en pantalla, pero se puede hacer fácilmente una copia de una URL a un archivo local en el disco duro utilizando urllib.
A veces se desea obtener un archivo que no es de texto (o binario) tal como una imagen o un archivo de video. Los datos en esos archivos generalmente no son útiles para ser impresos en pantalla, pero se puede hacer fácilmente una copia de una URL a un archivo local en el disco duro utilizando urllib.
![]() El método consiste en abrir la dirección URL y utilizar read para descargar todo el contenido del documento en una cadena (img) para después escribir esa información a un archivo local, tal como se muestra a continuación:
El método consiste en abrir la dirección URL y utilizar read para descargar todo el contenido del documento en una cadena (img) para después escribir esa información a un archivo local, tal como se muestra a continuación:
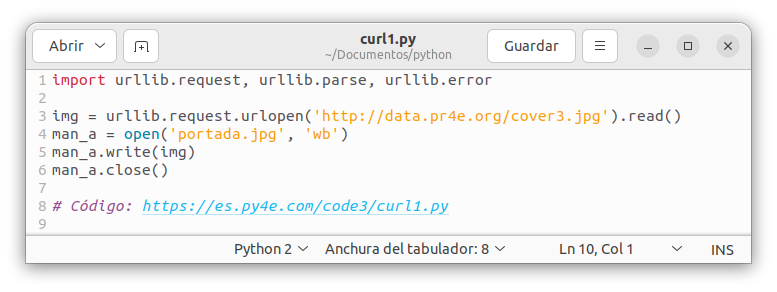
![]() Este programa lee todos los datos que recibe de la red y los almacena en la variable img en la memoria principal de la computadora. Después, abre el archivo
Este programa lee todos los datos que recibe de la red y los almacena en la variable img en la memoria principal de la computadora. Después, abre el archivo
portada.jpg y escribe los datos en el disco. El argumento wb en la función open() abre un archivo binario en modo de escritura solamente. Este programa funcionará siempre y cuando el tamaño del archivo sea menor que el tamaño de la memoria de la computadora. Usamos el comando «ls -l» para comprobar que el archivo de la imagen se ha grabado en nuestro equipo.
![]()

![]() Aún así, si es un archivo grande de audio o video, este programa podría fallar o al menos ejecutarse sumamente lento cuando la memoria de la computadora se haya agotado. Para evitar que la memoria se termine, almacenamos los datos en bloques (o buffers) y luego escribimos cada bloque en el disco antes de obtener el siguiente bloque. De esta forma, el programa puede leer archivos de cualquier tamaño sin utilizar toda la memoria disponible en la computadora.
Aún así, si es un archivo grande de audio o video, este programa podría fallar o al menos ejecutarse sumamente lento cuando la memoria de la computadora se haya agotado. Para evitar que la memoria se termine, almacenamos los datos en bloques (o buffers) y luego escribimos cada bloque en el disco antes de obtener el siguiente bloque. De esta forma, el programa puede leer archivos de cualquier tamaño sin utilizar toda la memoria disponible en la computadora.

![]() En este ejemplo, leemos solamente 100,000 caracteres a la vez, y después los escribimos al archivo portada.jpg antes de obtener los siguientes 100,000 caracteres de datos desde la web.
En este ejemplo, leemos solamente 100,000 caracteres a la vez, y después los escribimos al archivo portada.jpg antes de obtener los siguientes 100,000 caracteres de datos desde la web.
![]() Este programa se ejecuta como se observa a continuación:
Este programa se ejecuta como se observa a continuación:



Debe estar conectado para enviar un comentario.