![]() En esta aplicación, realizaremos algunas de las funciones de un motor de búsqueda. Primero rastrearemos una pequeña parte de la web y ejecutaremos una versión simplificada del algoritmo de clasificación que usa Google para determinar qué páginas se encuentran más conectadas. Luego, visualizaremos la clasificación de las páginas y conectividad de nuestro pequeño rincón de la web. Usaremos la librería de visualización de JavaScript D3 http://d3js.org/ para generar la imagen de salida.
En esta aplicación, realizaremos algunas de las funciones de un motor de búsqueda. Primero rastrearemos una pequeña parte de la web y ejecutaremos una versión simplificada del algoritmo de clasificación que usa Google para determinar qué páginas se encuentran más conectadas. Luego, visualizaremos la clasificación de las páginas y conectividad de nuestro pequeño rincón de la web. Usaremos la librería de visualización de JavaScript D3 http://d3js.org/ para generar la imagen de salida.
![]() Puedes descargar y extraer esta aplicación desde:
Puedes descargar y extraer esta aplicación desde:
www.py4e.com/code3/pagerank.zip
![]() El primer programa (spider.py) rastrea un sitio web y envía una serie de páginas a la base de datos (spider.sqlite), guardando los enlaces entre páginas. Puedes reiniciar el proceso en cualquier momento eliminando el fichero spider.sqlite y ejecutando de nuevo spider.py.
El primer programa (spider.py) rastrea un sitio web y envía una serie de páginas a la base de datos (spider.sqlite), guardando los enlaces entre páginas. Puedes reiniciar el proceso en cualquier momento eliminando el fichero spider.sqlite y ejecutando de nuevo spider.py.

![]() En esta ejecución de ejemplo, le pedimos que rastree un sitio web y que recupere dos páginas. Si reinicias el programa y le pides que rastree más páginas, no volverá a revisar aquellas que ya estén en la base de datos. En cada reinicio elegirá una página al azar no rastreada aún y comenzará allí. De modo que cada ejecución sucesiva de spider.py irá añadiendo páginas nuevas.
En esta ejecución de ejemplo, le pedimos que rastree un sitio web y que recupere dos páginas. Si reinicias el programa y le pides que rastree más páginas, no volverá a revisar aquellas que ya estén en la base de datos. En cada reinicio elegirá una página al azar no rastreada aún y comenzará allí. De modo que cada ejecución sucesiva de spider.py irá añadiendo páginas nuevas.

![]() Se pueden tener múltiples puntos de partida en la misma base de datos —dentro del programa, éstos son llamados “webs”. La araña elige entre todos los enlaces no visitados de las páginas existentes uno al azar como siguiente página a rastrear.
Se pueden tener múltiples puntos de partida en la misma base de datos —dentro del programa, éstos son llamados “webs”. La araña elige entre todos los enlaces no visitados de las páginas existentes uno al azar como siguiente página a rastrear.
![]() Si quieres ver el contenido del archivo spider.sqlite, puedes ejecutar spdump.py, que mostrará algo como esto:
Si quieres ver el contenido del archivo spider.sqlite, puedes ejecutar spdump.py, que mostrará algo como esto:

![]() Esto muestra el número de enlaces hacia la página, la clasificación antigua de la página, la clasificación nueva, el id de la página, y la url de la página. El programa spdump.py sólo muestra aquellas páginas que tienen al menos un enlace hacia ella.
Esto muestra el número de enlaces hacia la página, la clasificación antigua de la página, la clasificación nueva, el id de la página, y la url de la página. El programa spdump.py sólo muestra aquellas páginas que tienen al menos un enlace hacia ella.
![]() Una vez que tienes unas cuantas páginas en la base de datos, puedes ejecutar el clasificador sobre ellas, usando el programa sprank.py. Simplemente debes indicarle cuántas iteraciones del clasificador de páginas debe realizar.
Una vez que tienes unas cuantas páginas en la base de datos, puedes ejecutar el clasificador sobre ellas, usando el programa sprank.py. Simplemente debes indicarle cuántas iteraciones del clasificador de páginas debe realizar.

![]() Puedes volcar en pantalla el contenido de la base de datos de nuevo para ver que la clasificación de páginas ha sido actualizada:
Puedes volcar en pantalla el contenido de la base de datos de nuevo para ver que la clasificación de páginas ha sido actualizada:

![]() Puedes ejecutar sprank.py tantas veces como quieras, y simplemente irá refinando la clasificación de páginas cada vez más. Puedes incluso ejecutar sprank.py varias veces, luego ir a la araña spider.py a recuperar unas cuantas páginas más y después ejecutar de nuevo sprank.py para actualizar los valores de clasificación. Un motor de búsqueda normalmente ejecuta ambos programas (el rastreador y el clasificador) de forma constante.
Puedes ejecutar sprank.py tantas veces como quieras, y simplemente irá refinando la clasificación de páginas cada vez más. Puedes incluso ejecutar sprank.py varias veces, luego ir a la araña spider.py a recuperar unas cuantas páginas más y después ejecutar de nuevo sprank.py para actualizar los valores de clasificación. Un motor de búsqueda normalmente ejecuta ambos programas (el rastreador y el clasificador) de forma constante.
![]() Si quieres reiniciar los cálculos de clasificación de páginas sin tener que rastrear de nuevo las páginas web, puedes usar spreset.py y después reiniciar sprank.py.
Si quieres reiniciar los cálculos de clasificación de páginas sin tener que rastrear de nuevo las páginas web, puedes usar spreset.py y después reiniciar sprank.py.

![]() En cada iteración del algoritmo de clasificación de páginas se muestra el cambio medio en la clasificación de cada página. La red al principio está bastante desequilibrada, de modo que los valores de clasificación para cada página cambiarán mucho entre iteraciones. Pero después de unas cuantas iteraciones, la clasificación de páginas converge. Deberías ejecutar prank.py durante el tiempo suficiente para que los valores de clasificación converjan.
En cada iteración del algoritmo de clasificación de páginas se muestra el cambio medio en la clasificación de cada página. La red al principio está bastante desequilibrada, de modo que los valores de clasificación para cada página cambiarán mucho entre iteraciones. Pero después de unas cuantas iteraciones, la clasificación de páginas converge. Deberías ejecutar prank.py durante el tiempo suficiente para que los valores de clasificación converjan.
![]() Si quieres visualizar las páginas mejor clasificadas, ejecuta spjson.py para leer la base de datos y escribir el ranking de las páginas más enlazadas en formato JSON, que puede ser visualizado en un navegador web.
Si quieres visualizar las páginas mejor clasificadas, ejecuta spjson.py para leer la base de datos y escribir el ranking de las páginas más enlazadas en formato JSON, que puede ser visualizado en un navegador web.

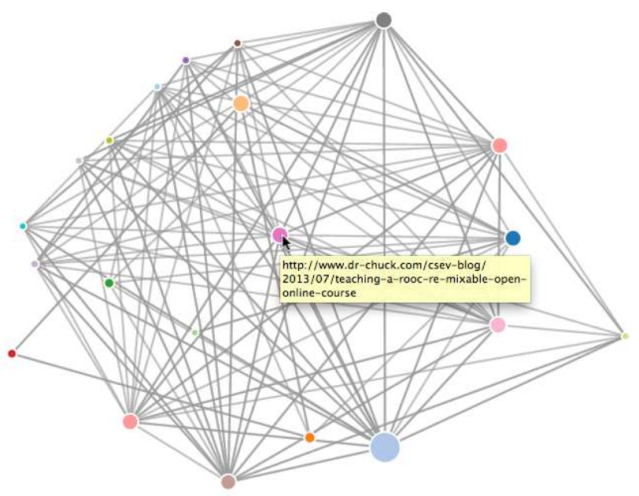
![]() Puede ver estos datos abriendo el archivo force.html en su navegador web. Esto muestra un diseño automático de los nodos y enlaces. Puede hacer clic y arrastrar cualquier nodo y también puede hacer doble clic en un nodo para encontrar la URL que representa el nodo.
Puede ver estos datos abriendo el archivo force.html en su navegador web. Esto muestra un diseño automático de los nodos y enlaces. Puede hacer clic y arrastrar cualquier nodo y también puede hacer doble clic en un nodo para encontrar la URL que representa el nodo.
![]() Si vuelves a ejecutar las otras utilidades, ejecuta de nuevo spjson.py y pulsa actualizar en el navegador para obtener los datos actualizados desde spider.json.
Si vuelves a ejecutar las otras utilidades, ejecuta de nuevo spjson.py y pulsa actualizar en el navegador para obtener los datos actualizados desde spider.json.


Debe estar conectado para enviar un comentario.